By Jayesh Gulani
Introduction to FLUX.1
FLUX.1, launched in August 2024 by Black Forest Labs, represents a significant advancement in the field of generative deep learning. This innovative model is designed to push the boundaries of creativity, efficiency, and diversity in media generation, particularly focusing on images and videos. With a mission to develop state-of-the-art generative models, FLUX.1 leverages advanced architectures such as flow matching and Denoising Image Transformer (DIT), similar to the technologies employed in Stable Diffusion 3 (SD3).
Key Features and Innovations
FLUX.1 is built on a robust foundation of 12 billion parameters, allowing it to deliver exceptional image fidelity and controllability. This model excels in generating high-quality images that cater to a wide range of applications, from artistic creations to detailed photorealistic outputs. The architecture combines the strengths of transformer models and diffusion techniques, enabling FLUX.1 to outperform its predecessors, including SDXL and SD1.5, in terms of image quality and prompt adherence.


Variants of FLUX.1
FLUX.1 comes in three distinct variants, each designed for different use cases:
FLUX.1 [Pro]
Performance: This is the flagship model, offering state-of-the-art performance with exceptional image quality, detail, and diversity.
Access: Available exclusively via API, making it suitable for commercial applications.
System Requirements: High system requirements, not suitable for consumer hardware.
FLUX.1 [Dev]
Purpose: A distilled version intended for non-commercial use, ideal for research and development.
Features: Provides similar quality and prompt adherence as the Pro version but is more efficient and can run on consumer hardware.
Availability: Open-weight model, downloadable for local use.
FLUX.1 [Schnell]
Speed: Optimized for fast image generation, making it suitable for local development and personal projects.
Performance: While it sacrifices some image fidelity for speed, it is designed for quick outputs.
License: Released under the Apache 2.0 license, allowing for broader usage.
Each variant caters to specific needs, from high-performance commercial applications to efficient local development and rapid prototyping.
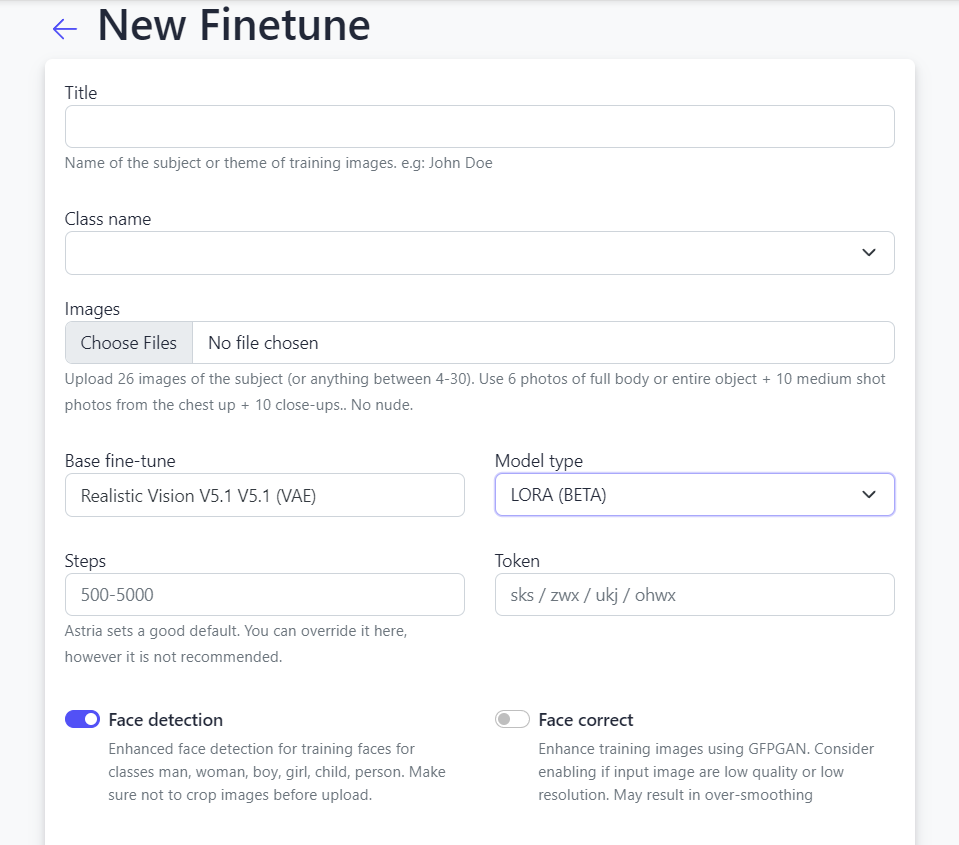
Fine-Tuning FLUX.1 on Astria.ai: Step-by-Step Guide
Fine-tuning FLUX.1 on Astria is easy: you just need a handful of images to get started.
Generate Your API Key
Before you can start fine-tuning FLUX.1, you'll need to generate an API key on Astria.ai. Here's how:
1. Login to Astria.ai: Visit Astria.ai and log in using your Gmail ID.
2. Access the API section: Once logged in, navigate to the API section of your account.
3. Generate the API Key: Click on the 'Generate API Key' button. This will create your unique API key, which you can use for all API requests.
4. $20 Free Credits: Upon generating your API key, you'll receive $20 in credits. These credits can be used to create fine-tunes and generate images using FLUX.1.
Guide to Fine-Tuning Human Faces
Here, we'll walk you through fine-tuning FLUX.1 using the API, specifically focusing on creating a model that excels at generating human face images. We'll use images of a woman from the free stock photo website, Pexels, to fine-tune our model.
- Prepare your data: Gather around 8-16 high-resolution images.
- Upload these images to PostImages to get the image URLs.
- Ensure that the images are diverse in terms of lighting, angles, and expressions to capture the full range of features you want the model to learn.
- Initiate fine-tuning: Replace YOUR_API_KEY and YOUR_MODEL_ID with your generated API key and Tune ID.
- Use the following code to fine-tune FLUX.1 for human faces:
import requests
from io import BytesIO
# Replace with your actual API key
API_KEY = 'YOUR_API_KEY'
# Function to download images and convert them to binary
def download_image(url):
response = requests.get(url)
if response.status_code == 200:
return BytesIO(response.content)
else:
print(f'Error downloading image: {url}, status code: {response.status_code}')
return None
# Fine-tune a model using Flux.1
def fine_tune_flux_model(api_key):
fine_tune_url = 'https://www.astria.ai/tunes'
image_urls = [
'https://i.postimg.cc/9fThRXgx/pexels-sound-on-3756747.jpg',
'https://i.postimg.cc/dttwHYD1/pexels-sound-on-3756750.jpg',
'https://i.postimg.cc/fysTTSwj/pexels-sound-on-3756752.jpg',
'https://i.postimg.cc/prPRtNZs/pexels-sound-on-3756917.jpg',
'https://i.postimg.cc/fRVZsfcQ/pexels-sound-on-3756944.jpg',
'https://i.postimg.cc/0yhvyKnM/pexels-sound-on-3756962.jpg',
'https://i.postimg.cc/LXKmNgZK/pexels-sound-on-3756993.jpg',
'https://i.postimg.cc/ZqyT8xnx/pexels-sound-on-3760859.jpg',
'https://i.postimg.cc/RF748Cc3/pexels-sound-on-3760918.jpg'
]
images = []
for url in image_urls:
image = download_image(url)
if image:
images.append(('tune[images][]', ('image.jpg', image, 'image/jpeg')))
fine_tune_data = {
'tune[class_name]': 'woman',
'tune[name]': 'woman',
'tune[title]': 'Flux Tune Model 1',
'tune[base_fine-tune]': 'Flux.1',
'tune[model_type]': 'lora',
'tune[branch]': 'flux1'
}
fine_tune_headers = {
'Authorization': f'Bearer {api_key}'
}
fine_tune_response = requests.post(fine_tune_url, headers=fine_tune_headers, data=fine_tune_data, files=images)
if fine_tune_response.status_code == 200:
tune_id = fine_tune_response.json()['id']
print(f'Fine-tuning started for tune ID: {tune_id}')
return tune_id
else:
print(f'Error fine-tuning model: {fine_tune_response.status_code}, {fine_tune_response.text}')
return None
# Main execution
flux_tune_id = fine_tune_flux_model(API_KEY)
6. Monitor the progress: Fine-tuning typically takes about 30-60 minutes. You can monitor this through the provided URL.
7. Generate the images: Once fine-tuning is complete, use the following code to generate images:
import requests
API_KEY = 'YOUR_API_KEY'
MODEL_ID = 1504994 # The hardcoded ID for the Flux model
# Generate images
def generate_images(api_key, model_id):
generate_url = f'https://www.astria.ai/tunes/{model_id}/prompts'
generate_data = {
'text': '<LoRA:`MODEL_ID`:1.0> sks woman In the style of TOK, a photo editorial avant-garde dramatic action pose of a person wearing 90s round wacky sunglasses pulling glasses down looking forward, in Tokyo with large marble structures and bonsai trees at sunset with a vibrant illustrated jacket surrounded by illustrations of flowers, smoke, flames, ice cream, sparkles, rock and roll',
'num_images': 4,
'model_type' :'lora',
'model': 'flux.1_dev'
}
generate_headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
generate_response = requests.post(generate_url, headers=generate_headers, json=generate_data)
if generate_response.status_code == 200:
prompt_id = generate_response.json()['id']
image_url = generate_response.json()['image_url']
print(f'Images generated for prompt ID: {prompt_id}')
print(f'Image URL: {image_url}')
else:
print(f'Error generating images: {generate_response.status_code}, {generate_response.text}')
# Main execution
generate_images(API_KEY, MODEL_ID)
# Main execution
generate_images(API_KEY, MODEL_ID)
Output

Prompt 2: A woman dressed in ornate, golden armour, holding a sword, standing on the battlefield at sunrise, with a determined expression.

Prompt 3: A woman driving a classic pink convertible with a shiny finish, reminiscent of a Barbie car, cruising down a candy-coloured boulevard lined with palm trees. She's wearing a stylish outfit in shades of pink and pastels, with oversized sunglasses and a bright smile. The scene is set in a whimsical, dreamlike world with cotton candy clouds, glittering starbursts in the sky, and playful details like oversized flowers and butterflies floating around

Guide to Fine-Tuning Pet Photographs
If you have a pet, here’s how you can fine-tune FLUX.1 to generate stunning new images.
1. Collect your data: Use diverse images of a pet, capturing different poses, environments, and expressions. Ensure the images are consistent in quality for the best results. I have used images of a golden retriever from Pexels.
2. The fine-tuning process: Follow the same steps as mentioned above for human faces, upload the images, and define your parameters. After completion, your model will be capable of generating new and fantastic pet images from your prompts.
Example Prompts
Prompt 1: A dog wearing cool sunglasses, lounging on a beach towel with the ocean in the background, under a colourful beach umbrella.

Prompt 2: A dog dressed in a tuxedo, sitting at a beautifully set dinner table with a candlelit ambience, looking classy and elegant.

How Flux.1 Compares to SD1.5 and SDXL
While SDXL and SD1.5 have been industry standards for a while, FLUX.1's use of flow matching and DIT architecture gives it a distinct edge.
Flux.1 has several key advantages over SD1.5 and SDXL:
Image Quality and Prompt Adherence
- Flux.1 achieves exceptional image fidelity, detail, and prompt adherence, setting a new standard for text-to-image generation.
- It adapts to a fitting cartoon drawing style while still adhering to prompts almost every time.
- Flux.1 successfully adhered to prompts in testing, outperforming the base SD3 model.
Versatility
- Flux.1 is more versatile than SD1.5, allowing the generation of many images that would be impossible with SD1.5 without specialized LoRAs or ControlNet.
- It works well for a wide range of use cases, from realistic to cartoon styles.
Summary and What’s Next
FLUX.1, especially when fine-tuned, provides a powerful tool for creators and developers. Whether you're looking to generate human portraits, artistic renditions, or even specific pet images, fine-tuning FLUX.1 using Astria's API opens up new possibilities. It is important to remember that Flux image prompting tends to give better outputs with a more narrative-style prompt rather than the traditional comma-separated tags. Also, what’s truly unique about Flux is its ability to render text – not just single words, but entire sentences – with great clarity. This feature alone opens up a universe of possibilities for businesses looking to integrate text into their images.